Technically, automation actually broke the day first, but if it weren’t for the automation and backups, I would have been in a world of hurt. Let me explain.
I currently have a Docker Swarm consisting of 6 Ubuntu server VMs spread over 2 physical Dell servers. This is my “production” cluster that run things that I want to be available all the time. My wife’s and my blogs are just 2 of the things that run in the production cluster. What I don’t have at present is a “non-prod” cluster that I can use to play with new things and break things without affecting the production apps. Sound familiar? It should. We’ve been doing this kind of thing in our work lives for ages. A couple of weeks ago I ordered some more RAM for the Dell servers so that I’d have the additional headroom to set up a non-prod Swarm to play. I also want to play with setting up a small Kubernetes cluster at some point so this upgrade will give me the ability to do both.
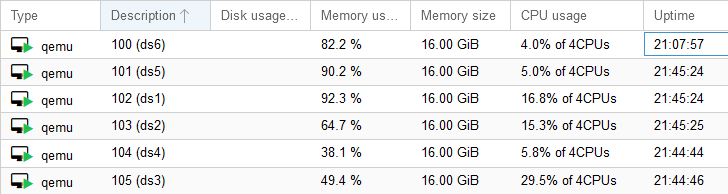
I mentioned in my Why I Homelab post a few weeks ago about using Ansible in my home lab to provision VMs and deploy applications. I took the time yesterday to set up a separate set of configuration files for my non-prod cluster via Ansible. I did a “dry run” with Ansible and everything looked okay. Nothing in my non-prod swarm configuration files even mentioned anything from my production swarm so I “pushed the botton” to deploy my brand new non-prod swarm.
I was monitoring the Proxmox UI and watched in horror as 5 of my 6 production VMs were first stopped and the removed–along with all the data that was contained on the Ceph volume shared between all the VMs. I sat in my chair stunned. My wife and I have put a lot of time into our blogs lately and I could just feel her wrath when I told her that we’d lost that data. So I didn’t tell her…until after I fixed it.
Having been down this road before and firmly believing in “when bad things happen” and not “if bad things happen”, I had set up Duplicati on the swarm to backup all the config files and working data that the applications in the cluster needed to function twice per day. I checked my Duplicati backup and, sure enough, just 3 hours prior we had a backup complete successfully. Side note: this was not the first time I had made sure I could restore from that backup.
Between having a backup of the data and having all my infrastructure configuration stored in a Git repo in the form of the Ansible tasks, I was able to have everything back up and running without any data loss in just over an hour. Had I not had the automation piece in place, I couldn’t have even recreated the 6 VMs in that amount of time, much less had a fully functioning system. Had I not had the data backup in place, my experiment with my home lab probably would have ended with my wife taking an axe to my server rack. So, in the end, I had a little over an hour of down time on our personal application stack, on a weekend, when we don’t get much traffic anyway. To the 1 or 2 of you that might have tried to access one of the apps here during that hour, my apologies, but I never signed an SLA 🙂
TL;DR Backup (and verify your backups) your data and spend some time automating everything you can because it’s not “if” something bad happens, it’s “when” something bad will happen.
Leave a Reply